
刚开始我手头有2个虚拟机,系统是Ubuntu 12.04,因此用其中一个安装所有ceph服务(包括mon、osd),一个作为admin节 点。后来尝试把admin节点也作为ceph client,发现Ubuntu 12.04的默认内核版本太低,不兼容rbd 。于是让同事新分配了一个新的虚拟机,Ubuntu 14.04系统,用作ceph client。3台vm都只有一个内网IP。测试服务的架构如下:
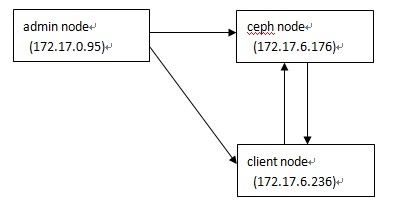
上述节点的作用说明如下:
- admin node: 仅作集中部署用途,运行ceph-deploy命令
- ceph node: 运行所有ceph服务,不过我这里只启用了mon、osd
- client node: 运行ceph的块存储客户端(rbd client)
(一)准备工作
首先设置3个vm的主机名,写在/etc/hosts里。ceph部署时使用短域名(hostname -s)识别服务器。
172.17.0.95 ceph.yygamedev.com ceph 172.17.6.176 ceph2.yygamedev.com ceph2 172.17.6.236 ceph3.yygamedev.com ceph3
在这3台vm里,创建ceph用户,设置该用户的sudo类型为NOPASSWD。然后退出系统,使用ceph用户重新登录。接着要配置vm的ssh服务,让admin节点的ceph用户可以不用密码登录另外两台服务器。关于ssh配置请参考这篇文档。
admin节点的~ceph/.ssh/config文件内容如下,我们的ssh服务使用非标准的9022端口。
Host ceph2 Hostname ceph2 User ceph Port 9022 Host ceph3 Hostname ceph3 User ceph Port 9022
接下来在admin节点上安装ceph-deploy工具,这个工具用来自动化安装ceph服务,非常方便。在admin节点上执行如下命令,增加release key:
wget -q -O- 'https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc' | sudo apt-key add -
将ceph包增加到系统的repo里:
echo "deb http://ceph.com/debian-firefly/ precise main" | sudo tee /etc/apt/sources.list.d/ceph.list
上述firefly是ceph的版本号,目前我用的firefly是2014 LTS版本,其他版本号请见:
http://docs.ceph.com/docs/master/releases/
最后更新repo并且安装ceph-deploy:
sudo apt-get update && sudo apt-get install ceph-deploy
(二)部署工作
(1)如下部署工作,如无特别说明,都在管理节点,使用ceph用户完成。首先创建一个专门的部署子目录:
mkdir my-cluster cd my-cluster
(2)如果你之前已经部署过ceph cluster,那么在正式部署之前,最好删除掉它们:
ceph-deploy purgedata ceph ceph2 ceph3 ceph-deploy forgetkeys
(3)现在创建一个全新的ceph cluster:
ceph-deploy new ceph2
这里的ceph2是mon服务的主机名。检查当前目录,你会发现多了一些东西。
(4)运行ceph-deploy对3台vm依次安装ceph服务:
ceph-deploy install ceph ceph2 ceph3
(5)初始化mon服务,收集key:
ceph-deploy mon create-initial
运行完后发现当前目录多了如下key文件:
ceph.bootstrap-mds.keyring ceph.bootstrap-osd.keyring ceph.client.admin.keyring
(6)增加3个osd。请注意ceph的默认复制策略是对同一文件保存3份副本,因此最少要有3个osd服务。典型的部署场景是一块物理磁盘对应一个osd,不过我的环境比较简单,只在ceph2这个vm里创建了3个子目录,每个目录对应一个osd进程。在ceph2的/data下创建3个子目录:
sudo mkdir /data/osd{0,1,2}
(7)回到管理节点,执行如下命令:
ceph-deploy osd prepare ceph2:/data/osd0 ceph2:/data/osd1 ceph2:/data/osd2 ceph-deploy osd activate ceph2:/data/osd0 ceph2:/data/osd1 ceph2:/data/osd2
第一个命令表示初始化osd,第二个命令表示激活osd.
(8)继续运行ceph-deploy admin命令将配置文件和key复制到所有节点:
ceph-deploy admin ceph ceph2 ceph3
(9)确保所有节点上,这个文件具有可读权限:
sudo chmod +r /etc/ceph/ceph.client.admin.keyring
(10)最后检查集群的健康状态:
$ ceph health HEALTH_OK
上述返回说明集群健康OK。
但是,这个安装后,返回的状态很可能不正常,还要调整一项crushmap参数。
首先获取当前的crushmap:
ceph osd getcrushmap -o /tmp/crushmap.original
/tmp/crushmap.original是一个编译过的文件,在编辑它之前必须反编译它:
crushtool -d /tmp/crushmap.original -o /tmp/crushmap
现在编辑/tmp/crushmap,如下行修改为:
step chooseleaf firstn 0 type osd
默认的应该是:
step chooseleaf firstn 1 type host
这里表示ceph的存储选择优先顺序,默认是按主机选择。我这里是在1个vm里运行3个osd,所以改成按osd选择。
修改完后,重新编译该文件:
crushtool -c /tmp/crushmap -o /tmp/crushmap.new
更新集群的clustermap:
ceph osd setcrushmap -i /tmp/crushmap.new
现在就OK了。再运行ceph health和ceph -s应该看到返回都正常。
(三)测试块设备
由于只安装了mon和osd,因此这里只测试ceph的rbd块设备服务。进入ceph3这个client节点,切换用户到root,如下命令都以root执行。
# 加载rbd内核模块: root@ceph3:~# modprobe rbd # 用rbd命令创建一个大小为1024MB的镜像: root@ceph3:~# rbd create test_image --size 1024 # 查看已有镜像: root@ceph3:~# rbd ls bar foo test_image foo2 foo3 # 将创建的镜像map到系统: root@ceph3:~# rbd map test_image # 显示已经map的镜像: root@ceph3:~# rbd showmapped id pool image snap device 0 rbd bar - /dev/rbd0 1 rbd test_image - /dev/rbd1 # 对map上的镜像格式化文件系统: root@ceph3:~# mkfs.ext4 -m0 /dev/rbd1 mke2fs 1.42.9 (4-Feb-2014) Discarding device blocks: done Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=1024 blocks, Stripe width=1024 blocks 65536 inodes, 262144 blocks 0 blocks (0.00%) reserved for the super user First data block=0 Maximum filesystem blocks=268435456 8 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376 Allocating group tables: done Writing inode tables: done Creating journal (8192 blocks): done Writing superblocks and filesystem accounting information: done # 创建一个目录用来挂载新文件系统: root@ceph3:~# mkdir /data/test_ceph_dir # 挂载文件系统: root@ceph3:~# mount /dev/rbd1 /data/test_ceph_dir/ # 展示已挂载的文件系统: root@ceph3:~# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda1 15G 2.6G 11G 19% / none 4.0K 0 4.0K 0% /sys/fs/cgroup udev 233M 4.0K 233M 1% /dev tmpfs 49M 804K 48M 2% /run none 5.0M 0 5.0M 0% /run/lock none 243M 0 243M 0% /run/shm none 100M 0 100M 0% /run/user /dev/rbd0 10G 162M 9.9G 2% /mnt/ceph-block-device /dev/rbd1 976M 1.3M 959M 1% /data/test_ceph_dir
进入/data/test_ceph_dir这个目录,就可以对新的块设备进行读写操作了。
在操作过程中,及时留意ceph集群的状态:
$ ceph -s
cluster 963a6787-0043-48e2-8677-a70f1564be17
health HEALTH_OK
monmap e1: 1 mons at {ceph2=172.17.6.176:6789/0}, election epoch 2, quorum 0 ceph2
osdmap e45: 3 osds: 3 up, 3 in
pgmap v44827: 384 pgs, 3 pools, 4865 MB data, 1585 objects
120 GB used, 102 GB / 235 GB avail
384 active+clean
上述所有384个pg都是active+clean状态即为正常。