
Borg是google的分布式任务系统,使任务在集群中得以执行,优化资源管理和避免单点故障。跟我们的升龙有点类似,当然功能比升龙强大很多。
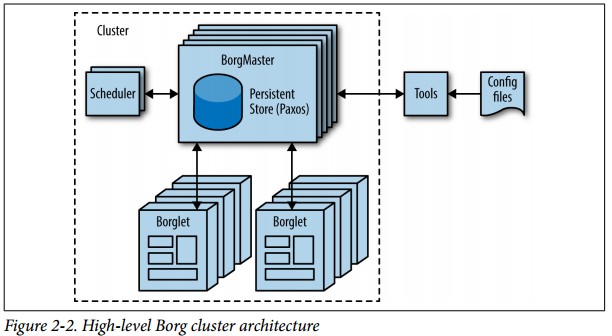
Borg is responsible for running users’ jobs, which can either be indefinitely running
servers or batch processes like a MapReduce [Dea04]. Jobs can consist of more than
one (and sometimes thousands) of identical tasks, both for reasons of reliability and
because a single process can’t usually handle all cluster traffic. When Borg starts a job,
it finds machines for the tasks and tells the machines to start the server program.
Borg then continually monitors these tasks. If a task malfunctions, it is killed and
restarted, possibly on a different machine.
Because tasks are fluidly allocated over machines, we can’t simply rely on IP addresses
and port numbers to refer to the tasks. We solve this problem with an extra level of
indirection: when starting a job, Borg allocates a name and index number to each task
using the Borg Naming Service(BNS). Rather than using the IP address and port
number, other processes connect to Borg tasks via the BNS name, which is translated
to an IP address and port number by BNS. For example, the BNS path might be a
string such as /bns/<cluster>/<user>/<job name>/<task number>, which would
resolve to <IP address>:<port>.
Borg is also responsible for the allocation of resources to jobs. Every job needs to
specify its required resources (e.g., 3 CPU cores, 2 GiB of RAM). Using the list of
requirements for all jobs, Borg can binpack the tasks over the machines in an optimal
way that also accounts for failure domains (for example: Borg won’t run all of a job’s
tasks on the same rack, as doing so means that the top of rack switch is a single point
of failure for that job).
If a task tries to use more resources than it requested, Borg kills the task and restarts
it (as a slowly crashlooping task is usually preferable to a task that hasn’t been restar‐
ted at all).