
对一个已知对象,可以根据CRUSH算法,查找它的存储结构。比如data这个pool里有一个文件resolv.conf:
$ rados -p data ls resolv.conf
显示它的存储结构:
$ ceph osd map data resolv.conf osdmap e43 pool 'data' (0) object 'resolv.conf' -> pg 0.9f1f5993 (0.13) -> up ([1,2,0], p1) acting ([1,2,0], p1)
输出结果说明:
- osdmap e43: 这是osdmap的epoll版本
- pool ‘data’: 这是pool名字
- object ‘resolv.conf’: 这是对象名字
- pg 0.9f1f5993 (0.13): 这是PG号
- up ([1,2,0], p1): 存储该PG的3个OSD都是活跃的,这是一个有序数组,第一个是primary OSD
- acting ([1,2,0], p1): 说明该PG存储在哪3个OSD里,同上也是有序数组
ceph osd map命令只是自己计算一遍CRUSH,它并不确认目标pool里是否真有这个对象,所以随便输入什么文件名,它总是返回成功。
关于对象在ceph里的存储,遵循如下示意图:
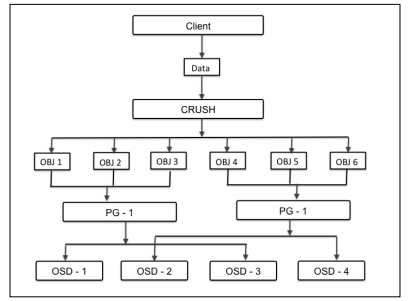
首先要存储的大数据(比如rbd设备),被打散成一系列小对象,每个对象会计算出它对应的PG号。取决于replication size的不同,每个PG会分布到多个OSD上。PG的全称是placement groups,它是一个逻辑存储单位,存在的目的是为了更好的管理和定位数以亿计的存储对象。
如何根据对象计算出PG号,以及PG号如何分布到具体的OSD上,这个就是CRUSH算法,如下示意图:
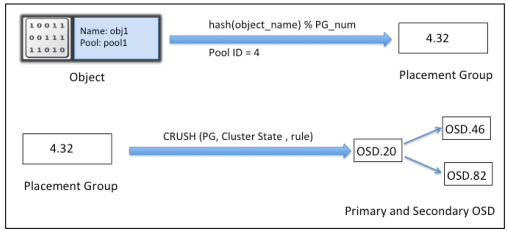
首先,根据对象名和pool里配置的PG数量(这些都已知),运用哈希函数计算出PG号。接下来根据PG号、集群状态、存储规则,运行CRUSH算法,找出具体负责存储的首要和次要OSD。最后客户端从这些OSD上对存储对象进行数据读和写。