如果某个OSD挂了,ceph集群开始进行rebalancing,丢失的对象被复制到其他健康的OSD。如果这个OSD在恢复后又重新加入集群,ceph再次进行rebalancing,将该OSD的数据补全,另外删除其他OSD上多余的对象。那么如何决定一个OSD是否挂掉?参考这篇文档:
http://docs.ceph.com/docs/master/rados/configuration/mon-osd-interaction/
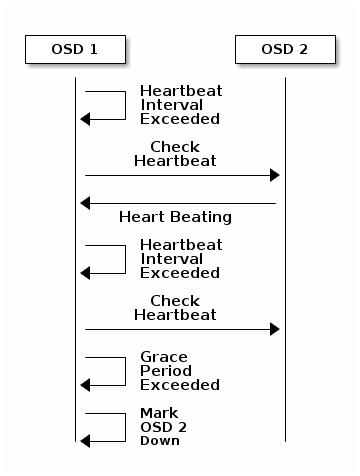
OSD相互的心跳检测
每个OSD每隔6秒钟检查其他OSD的心跳。假如某个OSD已经20秒没有检测到邻居OSD的心跳,该OSD就认为它的邻居已经挂了,并且报告给ceph monitor,monitor随之变更集群映射表。心跳时间可由osd heartbeat interval参数控制。
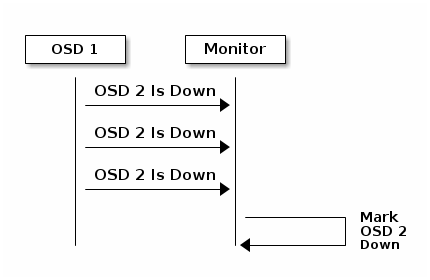
OSD报告邻居挂掉
默认情况下,OSD必须发送三次报告给monitor,告知邻居已经挂掉,然后monitor将挂掉的OSD标记为down。同样,正常情况下只需要一个OSD报告某个其他OSD已经挂了,但这个参数(mon osd min down reporters)以及前面的三次报告的参数(mon osd min down reports),都可以自己设置。
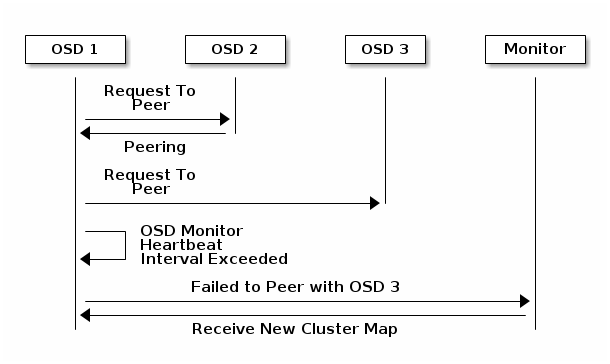
OSD与邻居通讯失败
假如某个OSD不能与其他任何一个OSD进行通讯,它将每隔30秒向monitor请求最新的集群映射表。请求间歇可由osd mon heartbeat interval参数控制。
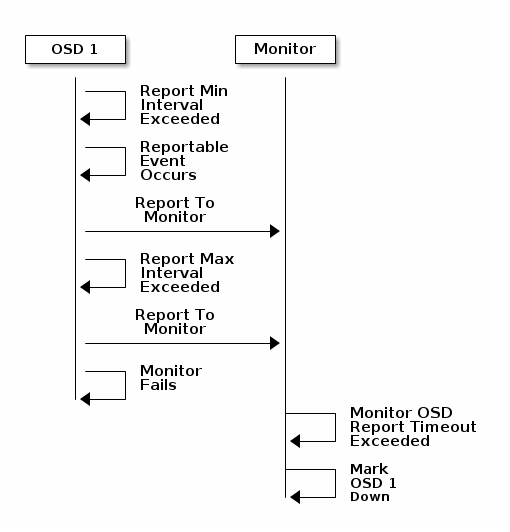
OSD报告自身状态
假如OSD不能给monitor发送报告,monitor在等待超时(mon osd report timeout)后,就认为该OSD已挂。OSD有事件发生时(比如故障、PG变更),或者它自身启动5秒内,会报告给monitor。控制最小报告周期的参数是osd mon report interval min,最大报告周期的参数是osd mon report interval max。后者默认是120秒,每隔120秒,不管有无事件发生,OSD都必须发送报告。