
我们有20几个ceph存储节点(host),分布在3个不同的机架(rack)上。这3个机架又位于机房的两排(row)里。因此ceph的存储结构,按照root -> row -> rack -> host这样进行布局。
在ceph集群里运行ceph osd tree命令看到如下输出:
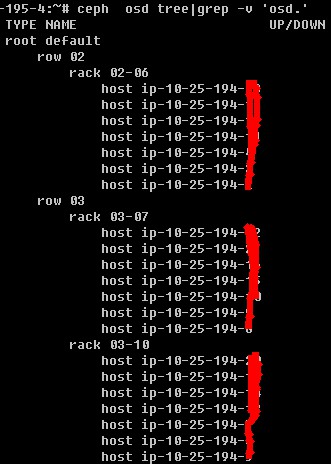
上述图示,在root下有row 02和row 03两排,在row 02下有rack 02-06这个机架,在row 03下有rack 03-07和rack 03-10两个机架。这三个机架分别接入不同的电源和网络设备,物理上具备冗余性。我们在设计数据存储逻辑时,让三个副本按机架进行分布,从而保障数据的冗余性。
这个布局需要调整ceph的CRUSH MAP。关于如何调整CRUSH MAP,使它按照设想的布局进行,请参考这篇文档。简单来说就是运行ceph osd crush add-bucket来增加row、rack两个逻辑单元,运行ceph osd crush move命令将host移动到rack下面,将rack移动到row下面,将row移动到root下面。当然,每个host下面包含若干OSD,这是在初始化安装时就设置好的。
数据写入时,如何保证分布到三个不同的机架,就需要在crushmap里定义存储rule。先把crushmap导出来到一个明文文件,修改这个文件,增加一节:
rule rack_replicated_ruleset {
ruleset 1
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type rack
step emit
}
关键在于step chooseleaf firstn 0 type rack这句,表明存储对象时,副本冗余性优先按机架(rack)的顺序进行选择。
改完crushmap文件后,再把它导入到集群里。关于如何导出、编辑和导入crushmap文件,请参考这篇文档。
改完crushmap后,接着创建所需要的pool,我们这里是4个:
ceph osd pool create pool1 16384 rack_replicated_ruleset ceph osd pool create pool2 2048 rack_replicated_ruleset ceph osd pool create pool3 2048 rack_replicated_ruleset ceph osd pool create pool4 2048 rack_replicated_ruleset
ceph osd pool create后面接的参数包括:pool名、pg_number、存储rule。rule使用刚才在配置文件里新增的rule。另外注意pg_number务必按照所需设置正确,并考虑一定的扩展性。如何设置pg_number,在ceph官方有个文档和计算器,很方便使用。我们计算结果的截图如下:
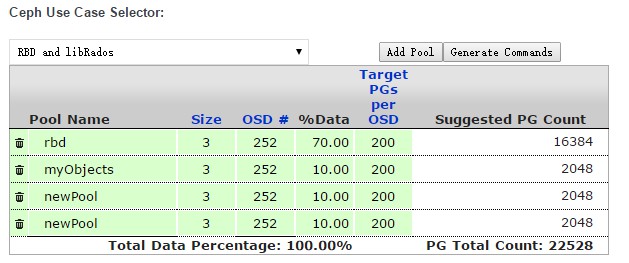
上述第一个pool主要存储rbd文件,设置为70%的容量,对应的pg_number也最大。
创建了pool,并且指定这个pool的存储规则为之前设置的rule,现在可以验证存储对象是否分布在三个不同的rack上。运行如下命令:
![]()
ceph osd map后面接的参数包括pool名字、存储的文件名(随意指定,存在或不存在皆可)。
我们看到这个文件位于180、146、92三个OSD里,再对照ceph osd tree的结果,可以确定它位于三个不同的机架上,从而保证了冗余性。关于ceph osd map的使用,请参考这篇文档。
ceph集群的安装使用ceph-deploy工具,关于如何安装请参考这篇文档。
安装后ceph.conf需要一定的调优,调优的参数在Learning Ceph一书的最后一章里,照着抄一遍,然后测试,找出适合自己的参数。调优参数没有最好的,只有最合适的。
最后,块存储的客户端(rbd client)使用了条带化参数来提高存储性能,示例如下:
rbd create image/myimage2 --size 102400 --object-size 32M --stripe-unit 65536 --stripe-count 32 --image-feature layering --image-feature striping