我们有20几个ceph存储节点(host),分布在3个不同的机架(rack)上。这3个机架又位于机房的两排(row)里。因此ceph的存储结构,按照root -> row -> rack -> host这样进行布局。
在ceph集群里运行ceph osd tree命令看到如下输出:
我们有20几个ceph存储节点(host),分布在3个不同的机架(rack)上。这3个机架又位于机房的两排(row)里。因此ceph的存储结构,按照root -> row -> rack -> host这样进行布局。
在ceph集群里运行ceph osd tree命令看到如下输出:
每年清明前后,珠海的木棉花便在大街小巷热烈的绽放,整个城市如笼罩在红霞中一般,美的令人窒息。以前我喜欢的情调是明媚、清纯,如桃花、杜鹃花。而现在发现即使是浓妆艳抹的木棉,也让我怦然心动。木棉之美,在于风姿卓越,一树红花在半天;在于热情奔放,数点红心向客开。
春深绝不见妍华,
极目黄茅际白沙。
几树半天红似染,
居人云是木棉花。
Google内部每个SRE team,都维护着简洁高效的监控系统。定义简单的规则、快速发现问题、找到问题本质,是监控的基线。尽可能减少监控告警带来的噪音,每个监控项,不仅发现问题,还要找到问题的本因。
Your monitoring system should address two questions: what’s broken, and why?
The “what’s broken” indicates the symptom; the “why” indicates a (possibly inter‐
mediate) cause. Table 6-1lists some hypothetical symptoms and corresponding
causes.

“What” versus “why” is one of the most important distinctions in writing good moni‐
toring with maximum signal and minimum noise.
SRE把大量重复性、手工性、没有结果的运维工作,定义为苦逼。SRE团队成员用于运维的时间不超过工作时间的一半,另一半时间用于研发。那么什么是苦逼的运维呢?
So what istoil? Toil is the kind of work tied to running a production service that
tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and
that scales linearly as a service grows. Not every task deemed toil has all these
attributes, but the more closely work matches one or more of the following descrip‐
tions, the more likely it is to be toil:
Google的产品质量指标体系包括SLI(service level indicators)、SLO(service level objectives)、SLA(service level agreements)。其中SLA是产品侧,主要面向外部用户。SLI和SLO是内部对质量的衡量指标。SLI的定义原则描述如下:
You shouldn’t use every metric you can track in your monitoring system as an SLI; an
understanding of what your users want from the system will inform the judicious
selection of a few indicators. Choosing too many indicators makes it hard to pay the
right level of attention to the indicators that matter, while choosing too few may leave
significant behaviors of your system unexamined. We typically find that a handful of
representative indicators are enough to evaluate and reason about a system’s health.
今天发现办公室访问公司网站,DNS解析多次发生问题。由于最近工信部推出国内网站需在国内注册商登记的调查问卷,怀疑网络封锁与此有关。我们看到com域有如下NS服务器:
com. 172800 IN NS i.gtld-servers.net. com. 172800 IN NS m.gtld-servers.net. com. 172800 IN NS f.gtld-servers.net. com. 172800 IN NS c.gtld-servers.net. com. 172800 IN NS g.gtld-servers.net. com. 172800 IN NS e.gtld-servers.net. com. 172800 IN NS b.gtld-servers.net. com. 172800 IN NS j.gtld-servers.net. com. 172800 IN NS l.gtld-servers.net. com. 172800 IN NS a.gtld-servers.net. com. 172800 IN NS k.gtld-servers.net. com. 172800 IN NS h.gtld-servers.net. com. 172800 IN NS d.gtld-servers.net.
运行如下查询,可看到这13台NS服务器有10台从办公室网络(电信光纤)无法抵达。
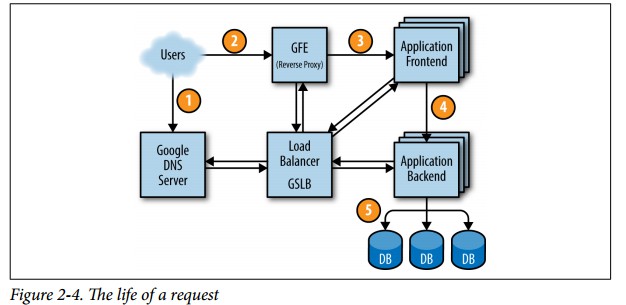
Google的服务响应也是一个多层处理架构。在广域网调度上使用GSLB进行最优路径寻址,在本地使用GSLB、BNS(名字服务)查找可用的服务器。应用服务包括前端和后端,两者异步运行,通过protobuf协议通信。这点同样与我们的升龙类似,升龙在广域网调度也使用了GSLB,而web专区的本地调度更为复杂一些,使用了OSPF、LVS、Nginx等协同作用。不过升龙没有使用名字服务,也没有将所有本地服务注册在GSLB里。