
As the new year approaches, it’s a good time to look forward to what the key trends will be, so we can take advantage of them thoughtfully and effectively.
Here are three key cloud trends I’m certain you’ll see unfold in 2016.
As the new year approaches, it’s a good time to look forward to what the key trends will be, so we can take advantage of them thoughtfully and effectively.
Here are three key cloud trends I’m certain you’ll see unfold in 2016.
风哥并不热爱驾驶,平时也挺宅的,假期偶尔会跑个小长途。因为有讴歌ZDX和奔驰C180这两款风格完全不同的车,日常中也经常使用,因此对比写一下两者的使用感受。

两车停到一起的合影。这款ZDX和C180都停产了。ZDX最后一批引进国内应该是2012年,而C180也是老款,2013年底是最后一批。不过,ZDX是彻底停产了,而C180是更新换代。新一代的C级外观更加漂亮,但新C180的发动机换成了1.6T,我这款是1.8T。
ceph管理里最常输入的命令可能是ceph health,它输出ceph的健康状态。
$ ceph health HEALTH_OK
如果返回不是HEALTH_OK就要注意,可能有PG处于非active + clean状态。对于有问题的PG,还可进一步运行ceph health detail命令,输出它们的详情。
$ ceph health detail HEALTH_OK
当然我这里没有问题PG存在,返回都是OK。
pool是ceph存储数据时的逻辑分区,它起到namespace的作用。其他分布式存储系统,比如Mogilefs、Couchbase、Swift都有pool的概念,只是叫法不同。每个pool包含一定数量的PG,PG里的对象被映射到不同的OSD上,因此pool是分布到整个集群的。
pool有两种方法增强数据的可用性,一种是副本(replicas),另一种是EC(erasure coding)。从Firefly版本起,EC功能引入。在EC里,数据被打散成碎片,加密,然后进行分布式存储。ceph由于其分布式能力,处理EC非常成功。pool在创建时可以设置这两种方法之一,但不能同时设置两者。
PG全称是placement groups,它是ceph的逻辑存储单元。在数据存储到cesh时,先打散成一系列对象,再结合基于对象名的哈希操作、复制级别、PG数量,产生目标PG号。根据复制级别的不同,每个PG在不同的OSD上进行复制和分发。可以把PG想象成存储了多个对象的逻辑容器,这个容器映射到多个具体的OSD。PG存在的意义是提高ceph存储系统的性能和扩展性。
CRUSH的全称是Controlled Replication Under Scalable Hashing,是ceph数据存储的分布式选择算法,也是ceph存储引擎的核心。在之前的博客里介绍过,ceph的客户端在往集群里读写数据时,动态计算数据的存储位置。这样ceph就无需维护一个叫metadata的东西,从而提高性能。
ceph分布式存储有关键的3R: Replication(数据复制)、Recovery(数据恢复)、Rebalancing(数据均衡)。在组件故障时,ceph默认等待300秒,然后将OSD标记为down和out,并且初始化recovery操作。这个等待时间可以在集群配置文件的mon_osd_down_out_interval参数里设置。在recovery过程中,ceph会重新产生受故障影响的数据。
在安装ceph的文档里,也提到了如何查看、编辑和更新crushmap。crushmap与ceph的存储架构有关,在实际中可能需要经常调整它。如下先把它dump出来,再反编译成明文进行查看。
$ ceph osd getcrushmap -o crushmap.original got crush map from osdmap epoch 56 $ crushtool -d crushmap.original -o crushmap
刚开始我手头有2个虚拟机,系统是Ubuntu 12.04,因此用其中一个安装所有ceph服务(包括mon、osd),一个作为admin节 点。后来尝试把admin节点也作为ceph client,发现Ubuntu 12.04的默认内核版本太低,不兼容rbd 。于是让同事新分配了一个新的虚拟机,Ubuntu 14.04系统,用作ceph client。3台vm都只有一个内网IP。测试服务的架构如下:
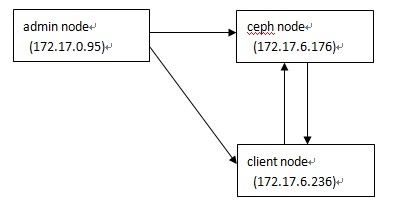
上述节点的作用说明如下:
对一个已知对象,可以根据CRUSH算法,查找它的存储结构。比如data这个pool里有一个文件resolv.conf:
$ rados -p data ls resolv.conf
显示它的存储结构:
$ ceph osd map data resolv.conf osdmap e43 pool 'data' (0) object 'resolv.conf' -> pg 0.9f1f5993 (0.13) -> up ([1,2,0], p1) acting ([1,2,0], p1)
输出结果说明:
ceph osd map命令只是自己计算一遍CRUSH,它并不确认目标pool里是否真有这个对象,所以随便输入什么文件名,它总是返回成功。